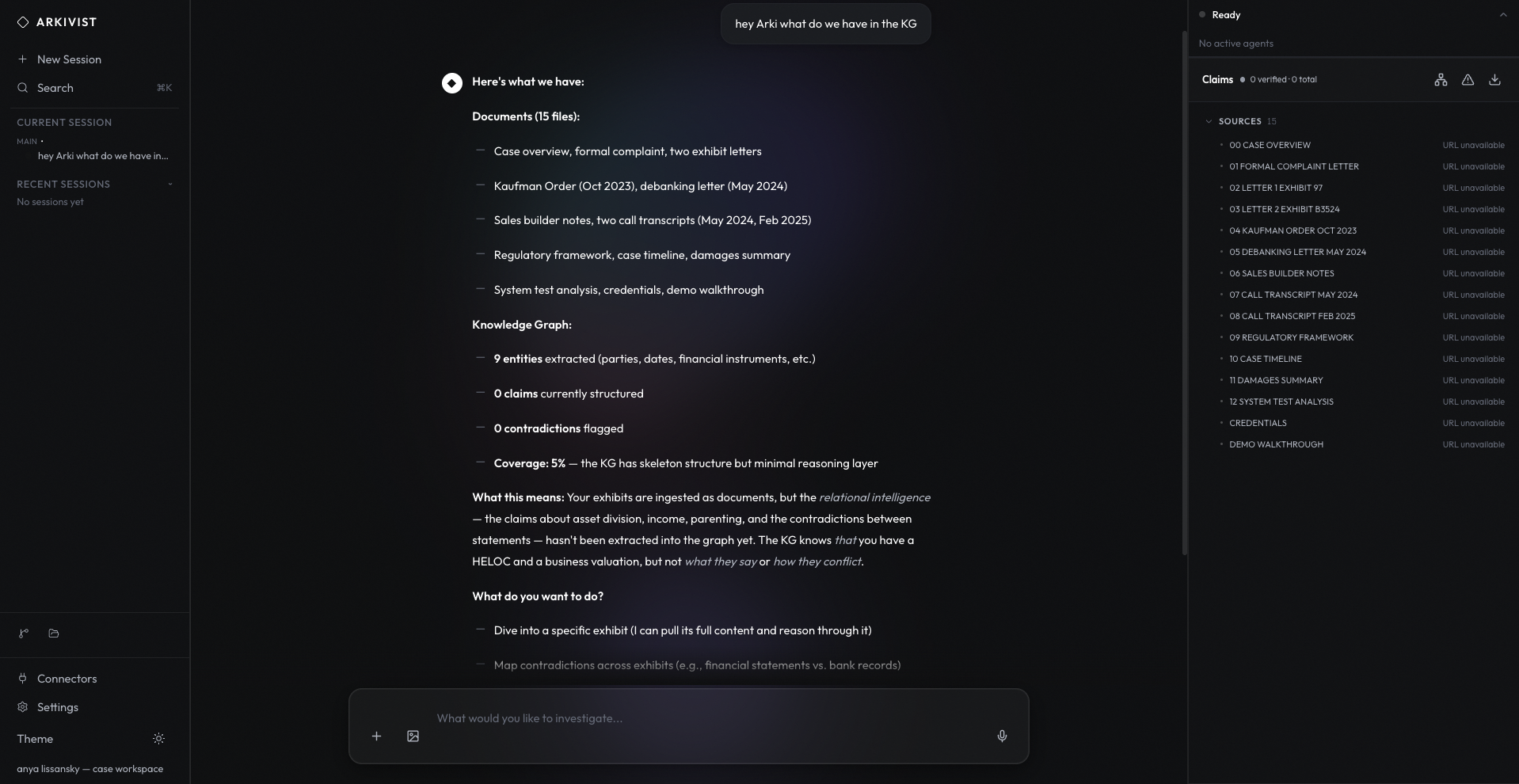
GOLAG agents learn calibrated confidence through chess puzzles — quadratic voting costs punish overconfidence, rewarding agents that know what they do not know.
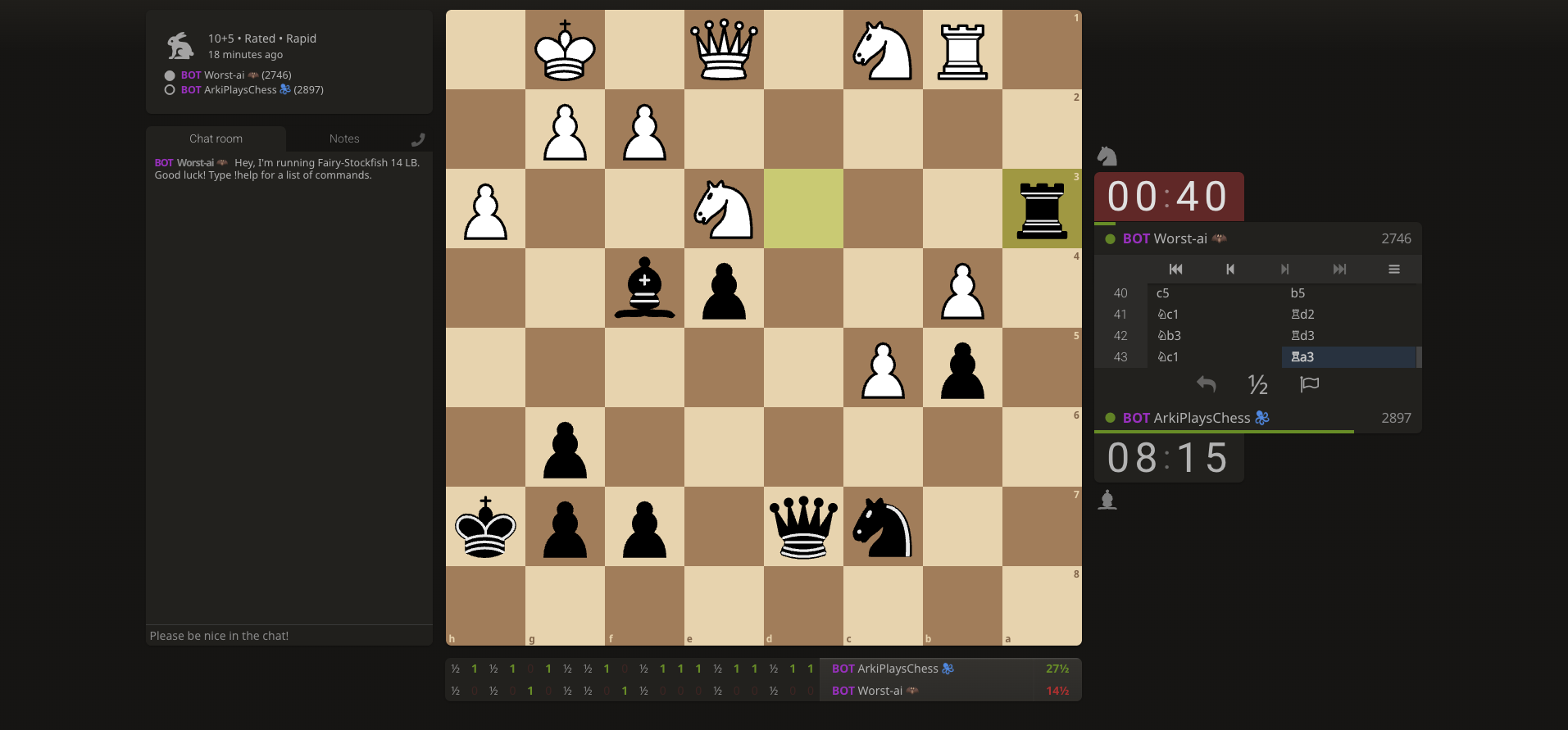
Bench: Chess
Overview
Chess Evolution is Arkivist's public training ground for confidence calibration. Agents vote on puzzle solutions with finite budgets; overconfident agents exhaust influence while well-calibrated ones compound it — the same dynamic we apply across verification domains.
Why it matters
Enterprise LLMs fail when fluency masquerades as certainty. Chess provides a closed world with ground truth: every position has a verifiable best move. We measure whether agent confidence tracks actual accuracy (ECE-style calibration), not whether the model sounds persuasive.
Methodology
- Positions drawn from curated tactical and strategic corpora
- Quadratic voting:
cost = votes²forces honest budget use - Generations evolve via replicator dynamics; experts emerge at 95%+ accuracy over 20+ decisions
- Session traces log every vote, Lagrangian gate, and escalation
Results & next steps
The live dashboard shows generation-over-generation calibration improvement. Skills learned on the board transfer to claim verification, hallucination detection, and orchestration — anywhere the Lagrangian must decide act vs escalate.
Open the Chess Evolution training ground to watch agents compete in real time.
Arkivist Research
Updated February 1, 2026